Overview
WeChat科普推文 第13期 · 2026-05-18
话题: in-context learning、上下文学习、Stack模型
不用重新训练!当单细胞AI学会了"现学现用"
返朴 | 第13期
2020年5月,OpenAI的一群研究人员在实验室里发现了一件让他们自己也目瞪口呆的事。
他们刚刚训练完GPT-3——一个1750亿参数的巨型语言模型。按照惯例,一个新模型出炉后,第一步就是"微调"(fine-tuning):拿特定任务的数据再训一轮,让它学会翻译、学会问答、学会写摘要。这就像一个新兵入伍后还要接受专业训练才能上岗。
但这次,有人突发奇想:如果不微调呢?如果直接在提示词里塞几个例子,告诉模型"这是英文→这是法文"、"这是问题→这是答案",然后直接问一个新问题,它会回答吗?
结果让他们激动得从椅子上跳了起来。GPT-3 在完全没有被训练过翻译任务的情况下,仅凭提示词里的三五个示例,就把一段英文准确地翻译成了法文。它不仅"看懂"了示例里的模式,还把这种模式现学现用到了全新的问题上。
这个现象后来被命名为 in-context learning(上下文学习),它被公认为大语言模型最令人震惊的"涌现能力"之一。它意味着模型的"学习"不再必须发生在训练阶段——它可以在推理的时候、在收到提示词的几毫秒内,当场学会一项新技能。
三年后,这个来自NLP(自然语言处理)领域的奇妙发现,悄然降临在了单细胞生物学的土地上。一群科学家问了一个大胆的问题:如果一段文字可以通过上下文示例让AI现学现用,那么一个细胞的基因表达谱——那种记录着两万个基因"谁高谁低"的数据阵列——是不是也可以?
答案是:可以。而且效果出奇地好。
一、什么是"上下文学习"?——用一家异国餐厅来解释
假设你飞到东京,走进一家全是日文菜单的小餐馆。你不认识任何一个日文单词,服务员也不会说中文。你怎么办?
你掏出手机,指着菜单上第一个菜"サーモン"——旁边有一张三文鱼的照片。第二个菜"マグロ"——旁边是金枪鱼。第三个菜"イカ"——旁边是鱿鱼。服务员端上来的和图片一模一样。
现在,你看到了第四个菜"エビ",没有图片,也没有翻译。但你突然意识到:你已经不需要图片了。 因为你从前面三个例子里"悟"出了这个菜单的命名逻辑——每个片假名词对应一种海鲜。
你不需要翻字典,不需要上日语课,甚至不需要记住任何语法规则。你只是看了看前面三行的对应关系,就把这种关系当场映射到了第四行。这就是上下文学习的精髓。
在机器学习的世界里,这个过程的正式定义是:模型在推理阶段,仅通过输入中提供的少量示例(称为"上下文"或"演示"),就能对全新样本做出正确预测,而模型的参数不发生任何改变。
注意最后半句——"参数不发生任何改变"。这意味着模型没有"学习"任何新东西,它只是"懂了"你给它的几个例子之间的模式,然后把这种模式套用到了新问题上。它是一种纯推理行为,不是训练行为。
打个比方:传统机器学习像学生上课——先听老师讲(训练),再参加考试(推理)。上下文学习则像开卷考试——你不需要提前学过这门课,但只要试卷前面附了几道例题和答案,你就能从例题里"悟"出解题思路,然后做出后面的题。
二、单细胞领域为什么迫切需要"现学现用"?
在单细胞生物学里,有一个经典困境,几乎困扰着每一个做数据分析的实验室。
假设你花了大半年时间,从某种罕见肿瘤组织中提取了5000个细胞,做了单细胞RNA测序。现在你需要给这5000个细胞标注类型——哪些是癌细胞,哪些是免疫细胞,哪些是基质细胞。传统做法是:找一个已经标注好的参考数据集,训练一个分类器,然后用它来预测你的5000个细胞。
问题来了:你的肿瘤组织里有一些只有20个细胞的稀有亚群。 在训练数据里,这个亚群根本不存在——没有任何分类器"学过"它的特征。更麻烦的是,你也不可能为了这20个细胞去重新训练整个模型——那就像为了修一根鞋带去开一家鞋厂。
这就是上下文学习能大显身手的地方。
在单细胞上下文学习框架中,你不需要重新训练任何东西。你只需要从你的5000个细胞里,手动标注出3到5个细胞作为"例题"——比如:"这个细胞是T细胞,那个是B细胞,那个是肿瘤细胞"——然后把这几个标注好的细胞连同所有未标注的细胞一起"塞"进模型。模型在几秒钟之内,就能根据你给的例题,为剩下的4995个细胞打出标签。
这就好像你走进一个新的细胞"城市",只需要认识三五个"本地居民",就能推断出全城几百万居民的"职业分布"。
三、Stack模型:把上下文学习"翻译"成细胞的语言
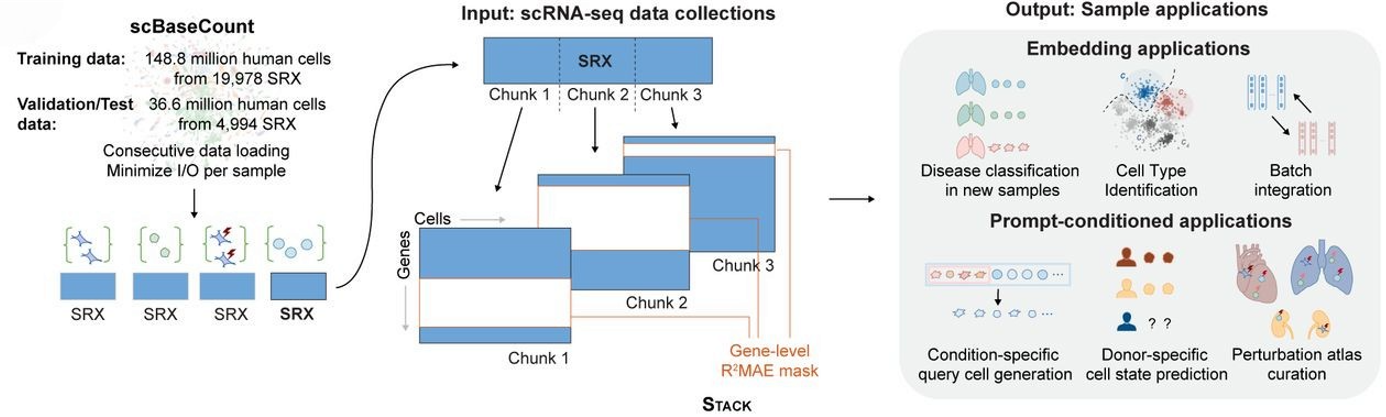
率先系统性地将上下文学习引入单细胞领域的,是来自陈-扎克伯格生物中心(CZ Biohub)和斯坦福大学的研究团队。他们在2024年发表了Stack模型(也称scBase模型家族),这是目前最大规模的单细胞上下文学习实验。
Stack模型的核心架构并不神秘——它就是一个标准的Transformer,和GPT系列模型师出同门。真正的创新在于它如何把"细胞"变成"上下文"。
在语言模型中,上下文是一串文字:"英文:hello → 法文:bonjour;英文:thank you → 法文:merci;英文:goodbye → 法文:____"。模型通过注意力机制(attention)自动找到"英文单词"和"法文单词"之间的映射关系,然后填上空白。
在细胞模型中,上下文是一串基因表达向量。每个细胞被表示为一个固定长度的数值向量(比如2000维),记录了每个基因在该细胞中的表达水平。几个标注好的细胞和它们的类型标签构成"例题",未标注的细胞则是"考题"。模型通过同样的注意力机制,自动找到"基因表达模式"和"细胞类型"之间的映射关系。
这背后的数学原理,藏在Transformer的自注意力机制(self-attention)里。简单来说,当模型"阅读"上下文中的每个细胞时,它会自动计算所有细胞之间的两两相似度——就像你在异国餐厅里,本能地去对比"サーモン"和"マグロ"这两个词的笔画结构,寻找它们和三文鱼、金枪鱼的对应规律。模型在无数次的预训练中,已经被"喂"过数千万个来自不同组织、不同物种的细胞数据,它已经内化了一套"细胞语法"——知道哪些基因喜欢一起高表达、哪些表达模式暗示着哪些生物学功能。上下文学习所做的,不过是激活这套已经内化的知识,让它聚焦在你提供的几个例题上。
用一句口诀总结:预训练给了模型"内功",上下文学习则是"招式"——三五个例题就能让模型把那身内功精准地使出来。 不需要重新练内功,换个对手(换一种任务),换几招就行。
四、不只是认细胞:上下文学习能干什么?
上下文学习在单细胞领域的应用远不止细胞类型注释。它的魔力在于:同一套"内功",换几个例题就能打不同的敌人。
第一,跨物种迁移。 你在小鼠身上标注了几个免疫细胞作为例题,Stack模型就能把这种"免疫识别能力"当场迁移到人类细胞上——不需要重新训练,不需要跨物种的数据对齐。因为预训练阶段它已经见过来自几十个物种的细胞,它"知道"小鼠T细胞和人类T细胞在基因表达上的"家族相似性"。
第二,基因扰动预测。 你想知道如果敲除基因X,细胞会发生什么变化?传统方法需要做CRISPR实验,耗时数月。在上下文学习框架下,你只需要给模型几个"已扰动"的细胞例题——"敲除基因A后,这些基因下调了"——模型就能推测敲除基因X的效果。它不一定是100%准确,但能在几秒钟内筛选出最可能的候选靶点,把实验验证的范围从几百个基因缩小到十几个。
第三,批次效应校正。 不同实验室、不同测序平台产生的数据存在系统性偏差——这就是我们之前聊过的批次效应。上下文学习中,你只需要在例题里放几个来自"参考批次"和"目标批次"的配对细胞,模型就能自动学会两种批次之间的"翻译规则",把目标批次的数据当场"翻译"成参考批次的样子。
第四,罕见病研究。 这是上下文学习最能发光发热的战场。罕见病患者数据稀少——可能只有十几二十个细胞。传统模型根本喂不饱。而上下文学习中,这十几个细胞恰好就是"例题"——不多不少,刚好够用。模型凭预训练阶段积累的"常识",能从这极少的示例中推断出疾病相关的基因扰动模式。
五、天下没有免费的午餐:上下文学习的局限
上下文学习虽然惊艳,但它并不是魔法。
第一个天花板是"上下文窗口"的大小。 Transformer模型的注意力机制有一个硬性上限——一次最多能"看"多少个细胞。当前的Stack模型语境窗口大约能容纳几百到几千个细胞。这对于大多数单细胞实验来说绰绰有余(一次标准10x实验大约产生5000-10000个细胞),但对于包含数百万细胞的图谱级数据集,就需要分批处理或采样策略。
第二个陷阱是"例题的选择"。 上下文学习的好坏极度依赖于你给模型看的"例题"质量。如果你给模型的三个例题恰好都是异常细胞(比如凋亡细胞、双胞体),它学到的模式就是错的,对后续细胞的全部分类也会系统性地跑偏。这就像你在异国餐厅里,如果前三个带图例的菜恰好是服务员端错盘的,你推断出的整个菜单逻辑就全乱了。
第三个局限在于"能力的边界"。 上下文学习只能激活模型在预训练阶段已经学到的模式。如果一个生物学概念(比如某种全新的基因调控机制)在预训练数据中完全没有出现过,那么无论你给多少例题,模型也无法"悟"出来。上下文学习是激活已有知识,而不是创造新知识。
六、一场静悄悄的革命
回顾单细胞数据分析的方法论演变,我们能清晰地看到三条分界线。
第一代是人工标注时代(卡哈尔式的显微镜观察 → 标记基因手工比对)。第二代是监督学习时代(训练一个细胞分类器 → 在新的数据集上预测)。第三代是预训练-微调时代(scGPT、Geneformer——先在海量数据上预训练,再在特定任务上微调)。
而现在,上下文学习正在叩响第四代的大门:预训练后无需微调,直接通过上下文示例完成任意下游任务。
这和NLP领域的历史轨迹何其相似。2020年的GPT-3证明了大语言模型可以"现学现用",2022年的ChatGPT把它变成了亿万用户触手可及的日常体验。单细胞领域正在经历同样的"方法论跃迁"——只是晚了三年。
但晚三年并不意味着不重要。恰恰相反:在生物医学领域,一个不需要重新训练、不需要GPU集群、不需要机器学习博士学位就能使用的AI工具,可能会以比ChatGPT更大的力度降低技术门槛。一个在县城医院工作的病理科医生,也许只需要在界面里圈出三五个典型细胞,AI就能在几秒内完成对整张切片上全部细胞的分类——这才是上下文学习最激动人心的前景。
它让"用AI分析单细胞数据"这件事,从"请一个机器学习工程师干一周"变成了"任何一个生物学研究生花五分钟就能搞定"。
这不是取代科学家。这是让科学家跑得更快。
一句话总结:上下文学习让单细胞大模型获得了"举一反三"的能力——不需要重新训练,只需看一眼你给的几个示例,它就能当场学会一项全新的分析任务。
延伸阅读:Theodoris, C. et al. (2023). Transfer learning enables predictions in network biology. Nature. | Cui, H. et al. (2024). scGPT: toward building a foundation model for single-cell multi-omics. Nature Methods. | Heimberg, G. et al. (2024). A foundation model for single-cell biology using in-context learning on transcriptomic data. bioRxiv.
Publication
Stack: In-Context Learning of Single-Cell Biology