Multimodal: 一个细胞,三种语言:多模态大模型如何让AI读懂细胞的全部秘密
Multimodal single-cell models integrating multiple data types.
Overview
WeChat科普推文 第9期 · 2026-05-14
话题: 多模态单细胞大模型、scRNA+ATAC+蛋白
从前,有六个盲人摸象。摸到腿的说大象像柱子,摸到耳朵的说像蒲扇,摸到尾巴的说像绳子。他们吵得不可开交,却没人知道,大象到底是什么样。
如果你觉得这个寓言只属于幼儿园课本,那你可能低估了它——过去二十年,单细胞生物学家几乎每天都在"摸象"。
一个细胞,就像一个微观世界里的大象。有人用单细胞RNA测序测量它正在表达哪些基因,有人用ATAC测序探测哪些DNA区域"门户大开、随时待命",还有人用抗体标记细胞表面的蛋白质。每一组数据都真实、都有价值,却各自只窥见了细胞的一个侧面。
真正的挑战是:同一个细胞,同时讲出三种"语言",AI能全部听懂吗?
这就是多模态单细胞大模型要回答的问题。
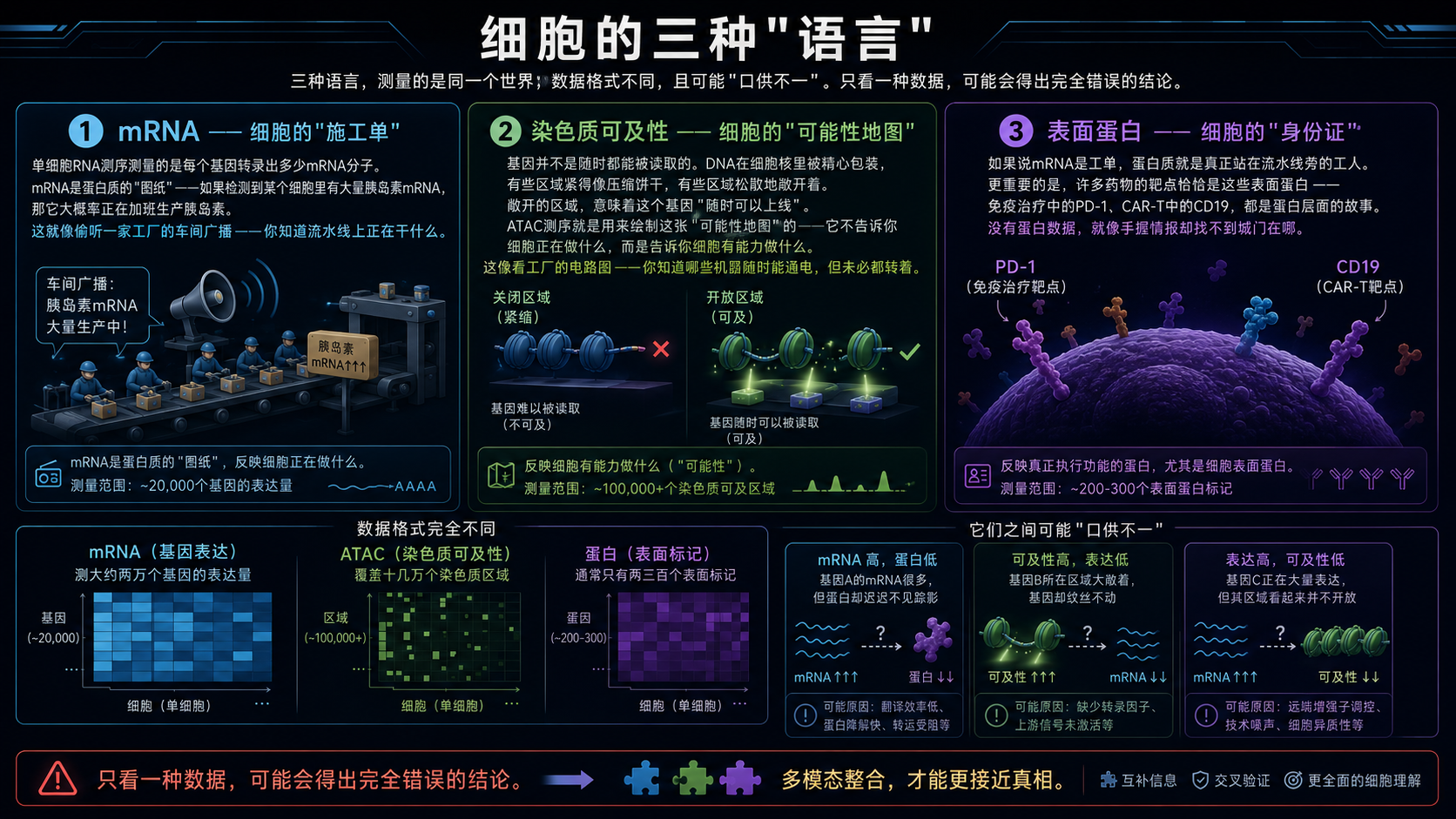
细胞的三种"语言"
要理解为什么要多模态,得先明白这三种数据各自在说什么。
第一种语言:mRNA——细胞的"施工单"。 单细胞RNA测序测量的是每个基因转录出多少mRNA分子。mRNA是蛋白质的"图纸"——如果检测到某个细胞里有大量胰岛素mRNA,那它大概率正在加班生产胰岛素。这就像偷听一家工厂的车间广播——你知道流水线上正在干什么。
第二种语言:染色质可及性——细胞的"可能性地图"。 基因并不是随时都能被读取的。DNA在细胞核里被精心包装,有些区域紧得像压缩饼干,有些区域松散地敞开着。敞开的区域,意味着这个基因"随时可以上线"。ATAC测序就是用来绘制这张"可能性地图"的——它不告诉你细胞正在做什么,而是告诉你细胞有能力做什么。这像看工厂的电路图——你知道哪些机器随时能通电,但未必都转着。
第三种语言:表面蛋白——细胞的"身份证"。 如果说mRNA是工单,蛋白质就是真正站在流水线旁的工人。更重要的是,许多药物的靶点恰恰是这些表面蛋白——免疫治疗中的PD-1、CAR-T中的CD19,都是蛋白层面的故事。没有蛋白数据,就像手握情报却找不到城门在哪。
三种语言,测量的是同一个世界。但它们的数据格式完全不同:mRNA测大约两万个基因的表达量,ATAC覆盖十几万个染色质区域,而蛋白质通常只有两三百个表面标记。这就像用三张比例尺不同、坐标系也不同的地图,拼一张完整的城市全景。
更要命的是,它们之间还可能"口供不一"——一个基因的mRNA水平很高,蛋白却迟迟不见踪影(转录后调控);一个染色质区域大敞着,基因却纹丝不动。只看一种数据,你可能会得出完全错误的结论。
翻译官的诞生:如何对齐三种语言
多模态单细胞大模型的核心任务,本质上是在做"翻译官"的工作:把三种语言映射到同一个"语义空间"里,让同一个细胞的三种表示彼此靠近。
怎么做?关键策略叫对比学习。
想象你教一个孩子同时学中文、英文和手语。你不会让他孤立背单词,而是给他看同一个苹果,同时用三种方式表达——"苹果"、"apple"、手势画圆。孩子的大脑中自然会形成关联:这三套符号,指向同一个东西。
多模态模型也是同样的逻辑。训练时,它看到的不是孤立的单组数据,而是配对的多模态数据——同一个细胞的RNA、ATAC和蛋白图谱,被同时喂给模型。模型学到的不是一个基因的高表达,不是一个染色质区域的开放,而是一个统一的"细胞表示"——这个向量里,融合了三种语言的全部信息。
技术上,这通常通过一个共享Transformer编码器实现。每种模态先经过自己专有的"分词器"(Tokenizer)——RNA有RNA的分桶策略,ATAC有ATAC的区域编码,蛋白有蛋白的特征提取——然后统统送进同一个Transformer网络。训练目标很明确:同一个细胞的三种模态表示,在向量空间中应该紧紧挨在一起;不同细胞的表示,应该远远分开。
这套思路借鉴了AI领域一个里程碑式的模型——OpenAI的CLIP。CLIP学会了把"猫的照片"和"猫这个字"映射到同一个向量位置,从而打通了图像和文字。多模态单细胞模型在做类似的事,只是把"图像"换成ATAC,"文字"换成RNA。
目前,领域内已有多款代表性模型:scVI系列的MultiVI同时处理RNA和ATAC,TotalVI整合RNA和蛋白;scGPT通过灵活的token设计天然支持多模态输入;华大基因的GeneCompass在超过一亿个细胞的跨物种数据上训练,具备多模态扩展能力;清华大学的scFoundation在多组学整合上做了重要探索。
能做什么:从"脑补"到"全息"
多模态模型的真正威力,不在于它多读了几种数据,而在于它获得了单模态模型不可能拥有的能力。
第一,跨模态预测——AI的"脑补"能力。 给你一个细胞的RNA数据,模型能推断出它的染色质状态和表面蛋白组成。这在临床上意义巨大:很多时候你只有一种数据,但做决策需要多维度信息。多模态模型可以从RNA"脑补"出蛋白和染色质——当然,这个"脑补"是建立在数千万细胞训练基础上的统计推断,不是凭空瞎猜。
第二,理解基因调控——分子生物学的圣杯。 ATAC数据告诉你哪些增强子开着门,RNA数据告诉你哪些基因在表达。把两者放进同一个模型,AI可以学习增强子与基因之间的调控关系:哪段非编码DNA在遥控哪个基因?这种"遥控器—灯泡"的配对,是分子生物学几十年来最核心的问题之一。传统方法需要大量实验一个个验证,而多模态模型可以用计算的方式提供全基因组范围的候选配对。
第三,疾病分析的"全息影像"。 疾病从来不是单一层面的故事。在癌症中,基因突变(DNA层面)→ 染色质重塑(表观层面)→ 转录失调(RNA层面)→ 蛋白异常(蛋白层面),这是一条环环相扣的链条。多模态模型可以同时捕捉四个层面的扰动,拼出一张更完整的病理图谱。以肿瘤免疫为例:模型能同时看到肿瘤细胞的免疫逃逸信号(蛋白)、T细胞的耗竭状态(RNA),以及双方染色质层面的"攻防部署"(ATAC)。
第四,模态不可知的分析——单细胞领域多年的梦。 当一个模型真正内化了多种模态的对应关系后,你给它任何模态的数据,它都能在同一个"细胞语义空间"里定位这个细胞。这意味着不同实验室、不同技术、不同模态产生的数据,可以放在同一个坐标系下比较——跨研究整合、跨平台对齐,不用再靠复杂的批次校正算法。
中国团队的角色
值得关注的是,中国团队在多模态单细胞模型赛道上的存在感很强。
2023年,华大基因推出了GeneCompass,一个基于超过一亿单细胞数据训练的多物种基础模型,在跨物种、跨组织的知识迁移上展现了强大能力,且具备多模态扩展的架构设计。清华大学自动化系团队开发的scFoundation在千万级细胞上预训练,对多组学整合做了系统探索。北京大学张泽民院士团队在肿瘤免疫微环境的多组学分析上持续产出里程碑式的工作,为多模态模型提供了高质量的生物学验证场景。
这背后有一个简单的逻辑:中国拥有全球最丰富的单细胞数据资源之一,华大基因的测序产能位居世界前列。在AI时代,数据就是石油,而中国在这一赛道上既有"油田"又有"炼油厂",这是一个结构性的优势。
尾声:罗塞塔石碑
1799年,拿破仑的士兵在埃及罗塞塔挖出一块黑色石碑。碑上刻着三种文字:古埃及象形文、平民体文字和古希腊文。正是这块石碑,让商博良最终破译了失传千年的古埃及文字——因为他手上有同一段内容的三个"平行版本"。
多模态单细胞大模型,某种程度上就是细胞生物学的罗塞塔石碑。三种"分子语言"刻在同一个细胞上,AI正在学习将它们一一对齐、互相翻译,用一段补全另一段,用已知推断未知。
当这一天真正到来,我们或许就不再是那个"摸象的盲人"。我们第一次有可能看见——这只叫做"细胞"的大象,到底长什么样。
一句话总结:多模态单细胞大模型让AI同时学习细胞的"施工单"(RNA)、"可能性地图"(ATAC)和"身份证"(蛋白),在三种分子语言之间建立翻译,像罗塞塔石碑一样,正在拼出细胞世界的第一张全景地图。