Geneformer
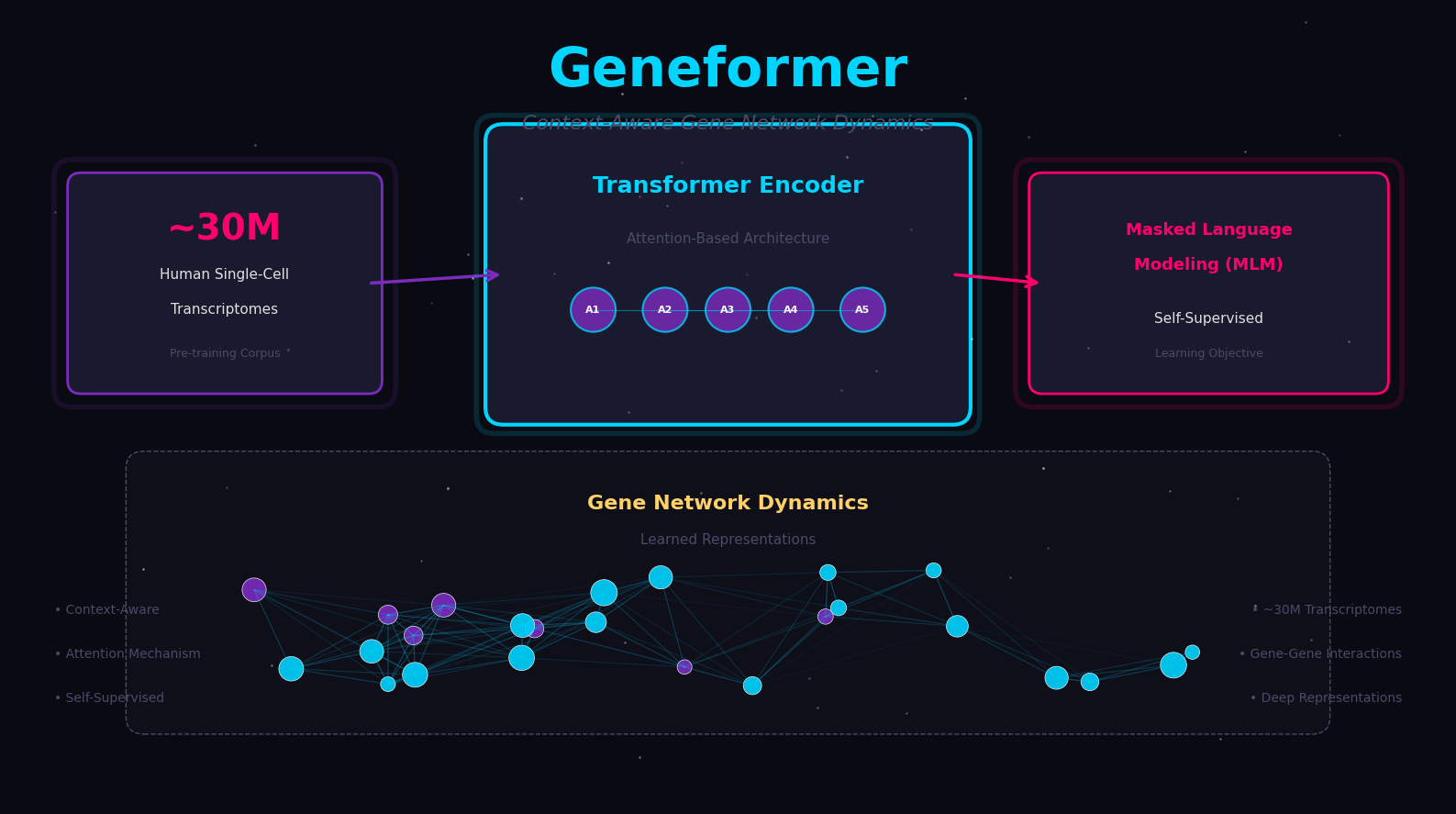
Context-aware foundation model for gene network predictions. Transfer learning from 30M single-cell transcriptomes.
Overview
WeChat科普推文 第5期 · 2026-05-10
话题: Geneformer、排序学习策略
不打分、不考试:Geneformer 只用"排序"就教会 AI 读懂 3000 万个细胞
返朴 | 第5期
2015 年,波士顿儿童医院的一间实验室里,Christina Theodoris 遇到了一件让她百思不得其解的事。
她正在研究一种罕见先天性心脏病——主动脉瓣疾病。她的团队辛辛苦苦从患者身上提取细胞,做成诱导多能干细胞(iPSC)模型,再分化成心肌细胞,然后测序、分析、找致病基因。一切按部就班。但结果让人沮丧:她只找到了几个已知的嫌疑基因。更深层次的基因调控网络——那些真正决定心脏是否正常跳动的"幕后黑手"——就像被浓雾笼罩,完全看不清。
原因说来简单,也让人无奈:罕见病的数据本来就少。你不可能从全世界收集到几千例主动脉瓣疾病患者的单细胞数据。传统的统计方法在这种"小样本"面前,就像用一根火柴去照整个体育场——光照到的地方有限,黑暗处你什么也看不见。
八年之后的 2023 年 5 月 31 日,Theodoris 在 Nature 上发表了一篇论文,题为《迁移学习实现网络生物学预测》(Transfer learning enables predictions in network biology)。这篇论文所描述的工具——Geneformer——不仅能从不到 50 个患者细胞中找出致病靶点,还能通过"零样本学习"(zero-shot learning)预测它从未见过的基因功能。更令人惊讶的是,它做到这一切靠的不是复杂的标签、不是昂贵的标注数据,而是一个简单到近乎"粗暴"的策略——给基因排序。
一、为什么不数数,要排序?
要理解 Geneformer 的精妙之处,我们先来做一个小游戏。
假设你有两个水果摊。摊 A 卖苹果、梨、西瓜;摊 B 也卖这三样。现在你要用一串数字描述每个摊的"水果特征"。最直觉的做法是:数数。摊 A 有 100 个苹果、3 个梨、50 个西瓜 → [100, 3, 50]。摊 B 有 30 个苹果、20 个梨、80 个西瓜 → [30, 20, 80]。
这就是传统单细胞转录组分析的思路:每个基因的表达量就是一个数字,全部数字合起来就是"细胞的画像"。
但问题来了:你换了一个测量工具(比如从 10x Genomics 平台换到 Smart-seq2),测出来的绝对数值可能差好几倍。这叫批次效应——我们在之前的内容里详细聊过。此外,"看家基因"(housekeeping genes)——那些在任何细胞里都高表达的基础代谢基因——总是霸占着数值排行榜的前列,真正能区分细胞身份的转录因子反而被淹没了。
Theodoris 的团队想了一个完全不同的办法:不数数,只排序。
就像你不再去数每个摊上各种水果有多少个,而是直接说:摊 A 卖得最好的是苹果,其次是西瓜,最后是梨 → 苹果第一、西瓜第二、梨第三。摊 B 卖得最好的是西瓜,其次是苹果,最后是梨 → 西瓜第一、苹果第二、梨第三。
你一眼就能看出来:摊 A 和摊 B 的经营策略完全不同。一个以苹果为主,一个以西瓜为主。这才是真正有意义的信息。
Geneformer 正是这样做的。它不读取每个基因的绝对表达量,而是把每个细胞里的基因按表达量高低排个名次。排名第一的基因得到 token "1",排名第二的得到 "2",以此类推。一个细胞就变成了一串数字——就像一句话是由一个个单词排列而成。
这种"排名编码"(rank value encoding)有三个绝妙的好处:
- 自动压制看家基因。GAPDH 这类基因虽然在几乎所有细胞中都高表达,但正因为如此,它在不同细胞之间的排名变异很小,模型自然学会了忽视它。
- 自动放大稀有但重要的基因。像转录因子 TBX5(正是 Theodoris 后来发现的候选靶点),表达量可能不高,但它在某些特定细胞中排名会突然跃升——这种跃升就是细胞状态的指纹。
- 天然抗批次效应。不管你用什么测序平台、什么实验条件,每个细胞内部基因的相对排序比绝对数值稳定得多。
二、学语言的 AI,怎么学会了"细胞逻辑"?
如果你读过我们这个系列的前几期,应该对"基因分桶"(gene binning)——scGPT 用的那种 tokenization 策略——不陌生了。scGPT 把表达量相近的基因分到同一个桶里,相当于把基因"粗粒度化"成离散的 token。
Geneformer 走上了相反的路:它不要粗粒度,而是保留精细的相对顺序。这背后的哲学很有意思:scGPT 相信"绝对值有意义,只是需要压缩";而 Geneformer 相信"绝对值的绝对值不可靠,相对顺序才是真理"。
两种路径各有千秋,但 Geneformer 的选择有一个意外收获:它自然地与 NLP(自然语言处理)领域最成功的预训练范式对齐了。
Geneformer 的预训练方法,几乎就是 BERT 的翻版:随机遮住每个细胞转录组中 15% 的基因,然后让模型根据剩下的基因,去猜被遮住的位置"应该是什么基因"。
这个训练任务有个专门的名字——掩码语言建模(Masked Language Modeling, MLM)。
举个例子。假设有一个心肌细胞的基因序列(已经按表达量排名):
MYH7 → TNNT2 → ACTC1 → [MASK] → TNNI3 → MYL2 → ...
模型看到的是:前面是高表达的心肌收缩蛋白 MYH7,后面是心肌特异性的肌钙蛋白 TNNI3……那中间那个空位里,最合理的答案应该是什么?如果你对心肌生物学有点了解,你会猜 ACTC1(α-心肌肌动蛋白)——一个在心肌中高表达的骨架蛋白。
Geneformer 就是在 3000 万个细胞上反复做这种"填空游戏"。没有任何人告诉它"这是心肌细胞""这是 T 细胞""这个基因和那个基因是相互激活的"。它仅仅通过"猜空缺基因"这个任务,就自监督地学会了基因之间的调控网络。
这就好比让一个孩子读 3000 万本没有标注类别的书,他可能说不出来"这本书是侦探小说、那本是言情小说",但他却潜移默化地学会了哪些词经常一起出现,哪些句子是合理的组合,哪些表达"读起来不对"。
Geneformer 学会的不是"分类",而是基因网络的内在逻辑。
三、排序学习的力量:从看家基因到关键调控因子
让我们稍微深入一点,看看这个排序策略为什么如此强大。
考虑两个基因:
- GAPDH(甘油醛-3-磷酸脱氢酶):一个典型的看家基因,几乎在所有细胞中都高表达。在 3000 万个细胞中,它可能一直排在每个细胞的前 100 名内。
- NKX2-5:一个早期心脏发育的关键转录因子,只在心脏祖细胞和心肌细胞中表达,表达量可能不高,但在特定发育窗口期非常关键。
在传统的绝对表达量系统中,GAPDH 永远是"显眼包"——它的数值(可能高达数千个 UMI count)会把 NKX2-5(可能只有几十个 count)完全淹没。任何基于数值的模型都会认为 GAPDH 比 NKX2-5 "更重要"。
但在 Geneformer 的排序系统里,情况完全不同了。因为 GAPDH 在所有细胞中都排得很靠前,所以它不携带细胞类型信息——所有细胞看起来都差不多。而 NKX2-5 虽然在绝大多数细胞中排得很靠后(甚至不在排名中),但在心脏祖细胞中会"嗖"地跃升到靠前的位置。这个跃升本身就是最强的信号。
通过在整个语料库(Genecorpus)中缩放每个基因的排名——即用基因在所有细胞中的全局表达程度来校正它在具体细胞中的排名——Geneformer 实现了一个精妙的去噪过程:高频但无信息量的基因被压制,低频但高信息量的基因被放大。
这就是为什么 Geneformer 在训练完成后,其注意力权重(attention weights)自然地编码了基因网络的层级结构——哪些基因是上游调控因子,哪些是下游效应基因,模型在"猜词"的过程中自己就搞清楚了。
四、只学不考,却能做题:零样本的魔法
Geneformer 预训练完成后最令人震惊的能力,不是它微调后能做得多好(虽然它确实在很多任务上超越了专门训练的模型),而是它的零样本学习能力。
什么叫零样本?就是模型从未见过这个任务,没有看过任何标注样例,直接让它做预测。
比如,Theodoris 的团队想找出心肌细胞中哪些基因对收缩功能最重要。传统的做法是:在实验室里挨个敲除基因,然后测量收缩力变化——这需要几个月甚至几年。而 Geneformer 的零样本方法只需几秒钟:在计算机里模拟基因敲除,看看细胞"状态"会变化多少。
他们的做法很巧妙:把某个基因从细胞排名中移除(模拟敲除),然后让模型重新预测这个位置本应是什么基因。如果模型预测的结果与原始基因相差很大,就说明这个基因在该细胞状态中"不可替代"——它是关键的调控节点。
用这种方法,他们找到了 TBX5——一个之前被认为主要与早期发育有关的转录因子。然后在真实的人 iPSC 来源心肌细胞中做实验验证:敲低 TBX5 确实大幅降低了心肌收缩力。更重要的是,在疾病模型中提升 TBX5 的表达可以显著改善心肌收缩功能——这意味着 TBX5 不仅是一个"嫌疑人",还是一个潜在的治疗靶点。
零样本找到的靶点,实验验证有效。这就像让一个从未学过心脏病学的学生,只看了一堆"细胞句子",就自己推理出哪个基因最关键——而且说对了。
五、从 3000 万到 1 亿:排序策略的可扩展性
Geneformer 最早版本(V1)在 2021 年 6 月完成训练,用的是约 3000 万个单细胞转录组数据,模型参数量 1000 万(10M)——放在今天的 AI 动辄几百亿参数的大模型面前,简直是个"小不点"。
但正是这个"小不点"排进了 Nature,获得了 200,000+ 访问和 1000+ 引用。
到了 2024 年底,Theodoris 团队发布了 Geneformer V2:训练数据扩大到 1.04 亿个细胞,模型参数量跃升到 1.04 亿(104M)和 3.16 亿(316M)两个版本,输入窗口也从 2048 个基因扩大到 4096 个。他们还增加了"癌症持续学习"变体——在 1400 万个癌细胞上继续训练,使模型具备了癌细胞特有的网络知识。
排序策略的优雅之处在于:它不依赖于数据的具体分布,所以训练数据量越大,学到的排序关系越稳健。 这完美契合了大模型的"规模法则"(scaling law)——更多的数据、更大的模型 = 更好的性能,没有天花板。
六、结语:少即是多的智慧
Geneformer 的故事给我们一个深刻的启示:在AI领域,有时候把信息扔掉,反而能看见真相。
扔掉绝对数值,保留相对排序——这看似丢失了信息,实则剥离了噪声。这种"少即是多"的哲学,恰好映照了科学史上许多伟大发现的共同特质:不是增加了什么,而是看透了什么该被忽略。
从 Theodoris 在实验室里为一小批罕见病患者细胞发愁,到 Geneformer 用 1 亿个细胞学会基因网络的底层语法,再到零样本发现心肌病治疗靶点——这是一条从"数据饥渴"到"数据智慧"的道路。而这条路上最关键的转折点,竟然只是一个改变:从"数数"变成"排序"。
✨ 一句话总结:Geneformer 的排序学习策略告诉我们,细胞的身份不在于基因表达了多少,而在于基因之间谁排在谁前面——去掉数字的绝对值,剩下的排名反而是更诚实的语言。
延伸阅读:
- Theodoris, C.V. et al. Transfer learning enables predictions in network biology. Nature 618, 616–624 (2023).
- Hugging Face 模型仓库:ctheodoris/Geneformer
- 官方文档:geneformer.readthedocs.io
Publication
Transfer learning enables predictions in network biology