TranscriptFormer
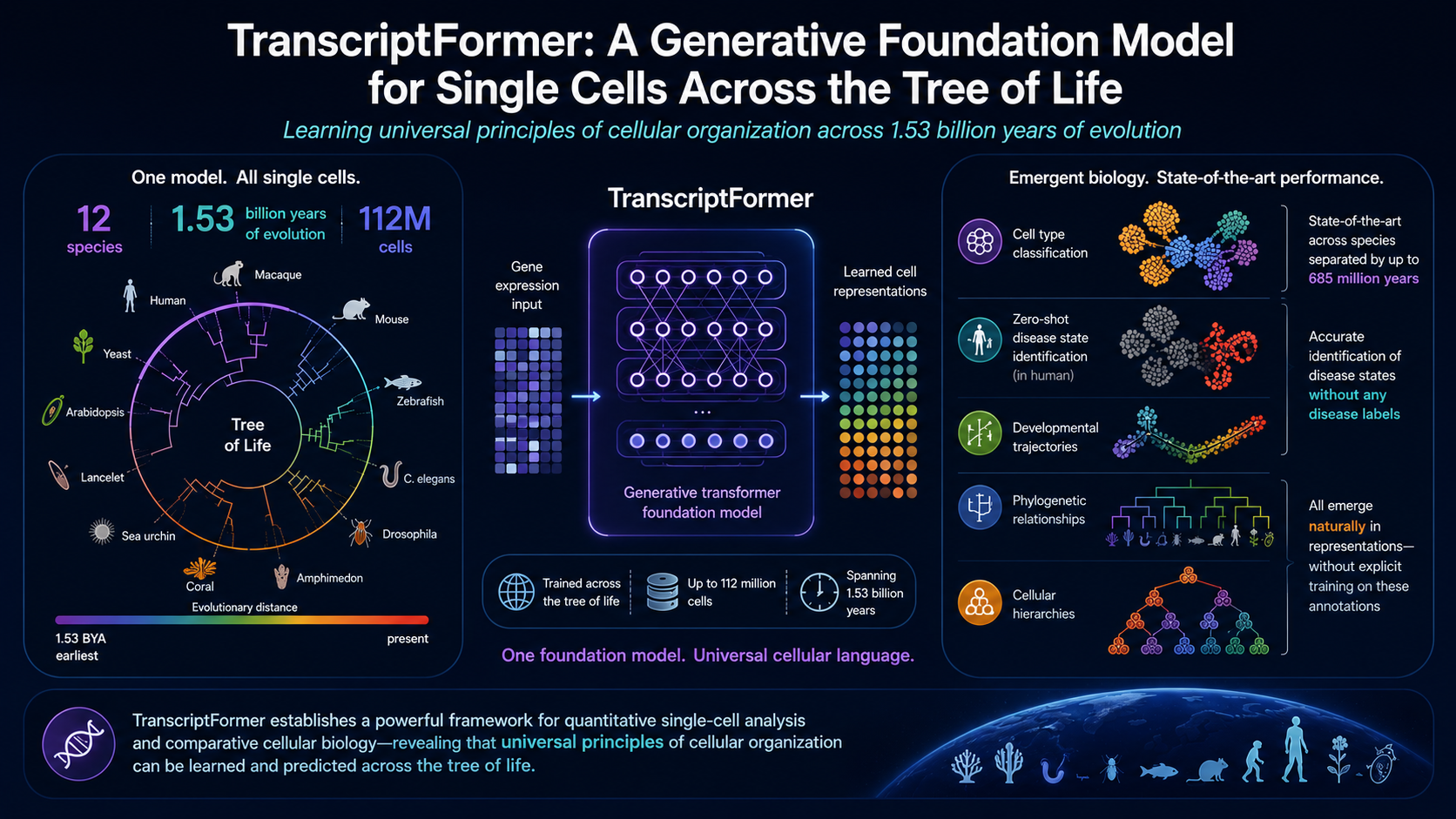
TranscriptFormer 用 5.4 亿参数、1.12 亿个细胞、12 个物种,在 one transformer 里读懂了从酵母到人类的"细胞通用语法"——跨物种细胞分类、零样本疾病识别、系统发育树涌现,单细胞大模型正式从"全基因组时代"跨入了"全演化树时代"
Overview
Science 在 2026 年 5 月 7 日在线发表单细胞演化大模型。
CZI(Chan Zuckerberg Initiative)的团队没有继续在"更多参数"的方向上卷。他们问了一个更根本的问题:
如果细胞的底层语言是跨物种共通的呢?
如果一个在海绵里工作的基因程序,和人类里相同的基因程序,在某种深层表示空间里是同构的——那我们为什么要在每个物种上分别训练一个 foundation model?
这是 TranscriptFormer 的核心假设。它做到了三件事:
1. 训练了一个跨 12 个物种的单一模型(从酵母到人类,覆盖 15.3 亿年的演化距离)
2. 模型能零样本识别未见过物种的细胞类型(跨越 6.85 亿年演化距离)
3. 系统发育关系和发育轨迹在模型中自发涌现——没有任何显式的演化树或发育阶段标签
架构:不是"多物种拼接",而是"统一基因语言"
TranscriptFormer 的架构哲学和前面三篇完全不同。scGPT 把基因当 token,Geneformer 把排名当输入,scFoundation 用不对称 attention 装下全基因组。TranscriptFormer 走得更远:它认为细胞不是"句子",而是"基因-表达式联合序列"。
核心创新一:基因 × 表达联合自回归建模
TranscriptFormer 是一个 生成式自回归联合模型。它对每个基因做两件事:
- 预测下一个基因是什么(哪个基因会出现)——这对应基因本体
- 预测这个基因的表达量是多少(raw count)——这对应表达水平
两个任务共用一个 transformer backbone,但对基因 token 和表达值分别有独立的输出头。损失函数是:
$$ \mathcal{L} = \mathcal{L}_\text{gene} + \lambda \cdot \mathcal{L}_\text{expression} $$
其中 $\mathcal{L}_\text{gene}$ 是交叉熵(gene token 分类),$\mathcal{L}_\text{expression}$ 是负二项似然(count data 的标准选择)。这让模型同时学到了"什么基因经常一起出现"和"它们通常以什么水平表达"。
核心创新二:表达感知多头自注意力(Expression-Aware MHA)
标准 Transformer 的自注意力只看 token embedding 的相似度。TranscriptFormer 在注意力计算中显式注入了基因表达值:
Attention(Q, K, V, expr) = softmax(QK^T / √d + expr_bias) · V
其中 expr_bias 是一个从基因表达值导出的可学习偏置项。这意味着两个基因是否互相"注意",不仅取决于它们的功能相似性,还取决于它们在当前细胞中表达了多高。高表达的基因会获得不成比例的注意力权重——这符合生物学直觉:一个 T 细胞疯狂表达 CD3,那它周围的免疫相关基因就应该被重点关注。
核心创新三:因果掩码 + 跨物种蛋白嵌入
TranscriptFormer 使用 causally masked self-attention(GPT 风格),这意味着它在做真正的下一基因预测。训练时看到前面 k 个基因,预测第 k+1 个;推理时可以做任意长度的条件生成。
怎么处理跨物种的基因对应关系?TranscriptFormer 不要求不同物种的基因一一对应。它用 ESM-2 蛋白语言模型为每个基因编码了一个蛋白质序列 embedding,作为该基因的"跨物种锚点"。所以:
- 人类的 TP53 和斑马鱼的 tp53 虽然名字不同,但因为蛋白序列相似,它们的蛋白质 embedding 在高维空间中很接近
- 模型自动学到了"这两个基因在不同物种里干的是类似的事"
- 对于训练时从未见过的物种(如猕猴、负鼠),只需要提供它们的蛋白质 embedding,模型就能 zero-shot 迁移
Publication
A Cross-Species Generative Cell Atlas Across 1.5 Billion Years of Evolution: The TranscriptFormer Single-cell Model
DOI: https://www.biorxiv.org/content/10.1101/2025.04.25.650731v2